Die Indexed Search Engine "indexed_search" ist trotz aller Alternativen (nicht nur) für mich noch immer die erste Wahl (und Standard) bei TYPO3 Projekten. Im Zusammenarbeit mit dem Site Crawler "crawler" kann man sehr schön die Inhalte – HTML Seiten wie PDFs –
indizieren vor allem dann, wenn man auch noch verschiedene FE-User Benutzergruppen hat und diese nur die ihnen zugedachten Inhalte finden sollen. So gehts:
Installation und Konfiguration der benötigten Extensions
Zuerst indexed_search installieren und das statische Template inkludieren, danach den crawler (der ohne statisches Template auskommt). Die Konfiguration der indexed_search geschieht im Extensionmanager. Hier sind drei Dinge zu beachten:
1. „Pfad zu den PDF-Parsern“ mit der Standardeinstellung /usr/bin/.
Kennt man sich auf und mit seinem Server aus, weiß man, was damit gemeint ist. Verwendet man einen Webspace bei einem Massenhoster sollte man überprüfen, ob der Pfad stimmt und ob die Tools vorhanden sind. Zu diesem Zweck gibt es ein kleines PHP Skript, das von hier stammt und dort auch beschrieben ist:
<?php error_reporting(E_ALL & ~E_NOTICE); ini_set('display_errors', 1); echo '<p>open_basedir: ' . ini_get('open_basedir') . '</p>'; if (is_file('/usr/bin/pdfinfo')) {; echo '<p>pdfinfo found</p>'; } else { echo '<p>pdfinfo not found</p>'; } ?> |
2. „Indizierung im Frontend deaktivieren“ – hier kann man ein Häkchen setzen, wenn man sich ganz auf die Indizierung durch den Crawler verlassen will.
3. „Crawler“-Erweiterung zum Indizieren externer Dateien verwenden“ – hier ist ein Häkchen für unsere Zwecke unerlässlich.
Hintergrund: standardmäßig werden die Inhalte per Aufruf der Seite indiziert und damit der Suche zugänglich gemacht. Das ist im Normalfall ausreichend, jedoch nicht bei der Verwendung von externen Dokumenten und vor allem nicht, wenn FE-Usergruppen existieren, da eine korrekte Indizierung ein Login in jeder Benutzergruppe voraussetzt. Das erledigt der crawler zuverlässiger.
Die Einstellungen des crawlers im Extensionmanager können für unseren Anwendungsfall beim Standard belassen werden.
Damit die Suche funktioniert und die Inhalte indiziert werden benötigt man – bekanntermaßen – folgende Minimalkonfiguration im TypoScript:
config { ... index_enable = 1 index_externals = 1 no_cache = 0 } |
Setzen wir voraus, dass es zwei FE-Usergruppen gibt (id 1 und id 2), dass bestimmte Seiten nur für die eine oder die andere Gruppe zugänglich sind und weiterhin, dass im Text PDF Dokumente verlinkt sind. Erreicht werden soll, dass die Inhalte so indiziert werden, dass sie nur für die jeweilige Benutzergruppe auffindbar sind.
Die „Crawler“ – Konfiguration erstellen
Zunächst muss ein crawler-Datensatz angelegt werden, mit dessen Hilfe die Konfiguration erledigt wird (früher geschah das über das TS Config). Gehen wir also im Listenmodul auf die Rootseite und legen einen neuen Datensatz an vom Typ "Crawler Configuration".
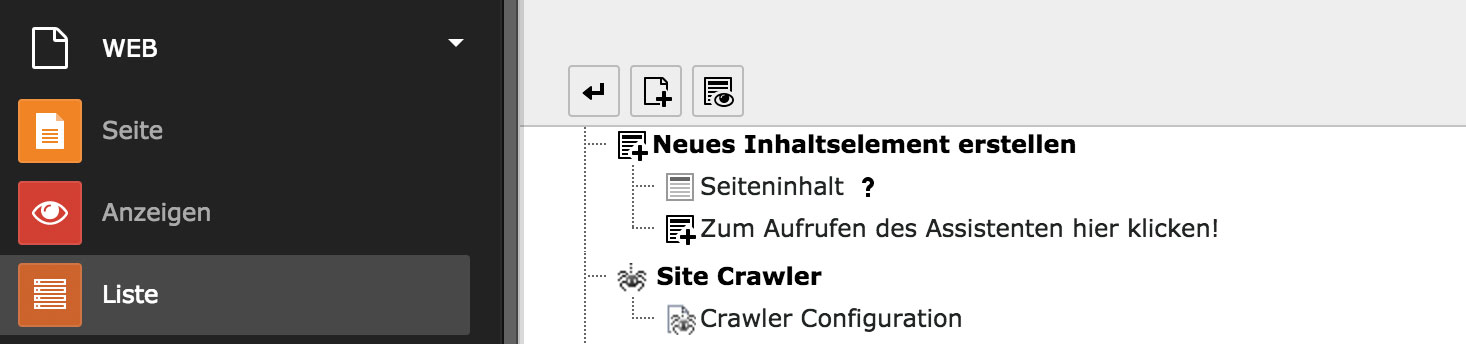
Abbildung 1
Hier wird zunächst ein Name vergeben, z.B. „indexingall“ und ein Häkchen gesetzt bei "Re-indexing [tx_indexedsearch_reindex]". Das Feld "Configuration" kann für unser Beispiel leer bleiben, jedoch muss die "Base url" angegeben werden (oder eben die Auswahl "Get Baseurl from Domainrecord" getroffen werden).
Alle anderen Felder bleiben leer.
Als nächstes erstellen wir zwei weitere, fast identische Datensätze nur dass jeweils einer für jede Benutzergruppe gilt. Es ändert sich also der Name (z.B „indexinggroup1“ und „indexinggroup2“) und bei "Crawl with FE usergroups" wird die jeweilige Benutzergruppe hinzugefügt.
Wir haben also drei Crawler-Konfigurationsdatensätze erstellt: einen für den nicht geschützten Bereich, einen für die Seiten der Usergruppe 1 und einen für die Seiten der Usergruppe 2.
Indizieren der Inhalte
Das eigentliche Indizieren kann nun auf 2 Arten erfolgen: entweder über das Modul „Info“ (Auswahl: „Site-Crawler“) oder, komfortabler, über einen Cronjob mit Hilfe des Moduls „Planer“ bzw. „Scheduler“.
Sehen wir uns zunächst an, wie der Indexierungsstatus der Seiten momentan ist. Das geht über das Modul „Indizierung“. Hier gibt es verschiedene Modi und Ansichten, außerdem besteht die Möglichkeit, Indizierungen zu löschen. Nehmen wir an, die Seiten sind momentan nicht indiziert und werden daher auch nicht gefunden: „Suche nach … Keine Ergebnisse gefunden“. Im einfachsten Fall sieht das dann so aus:
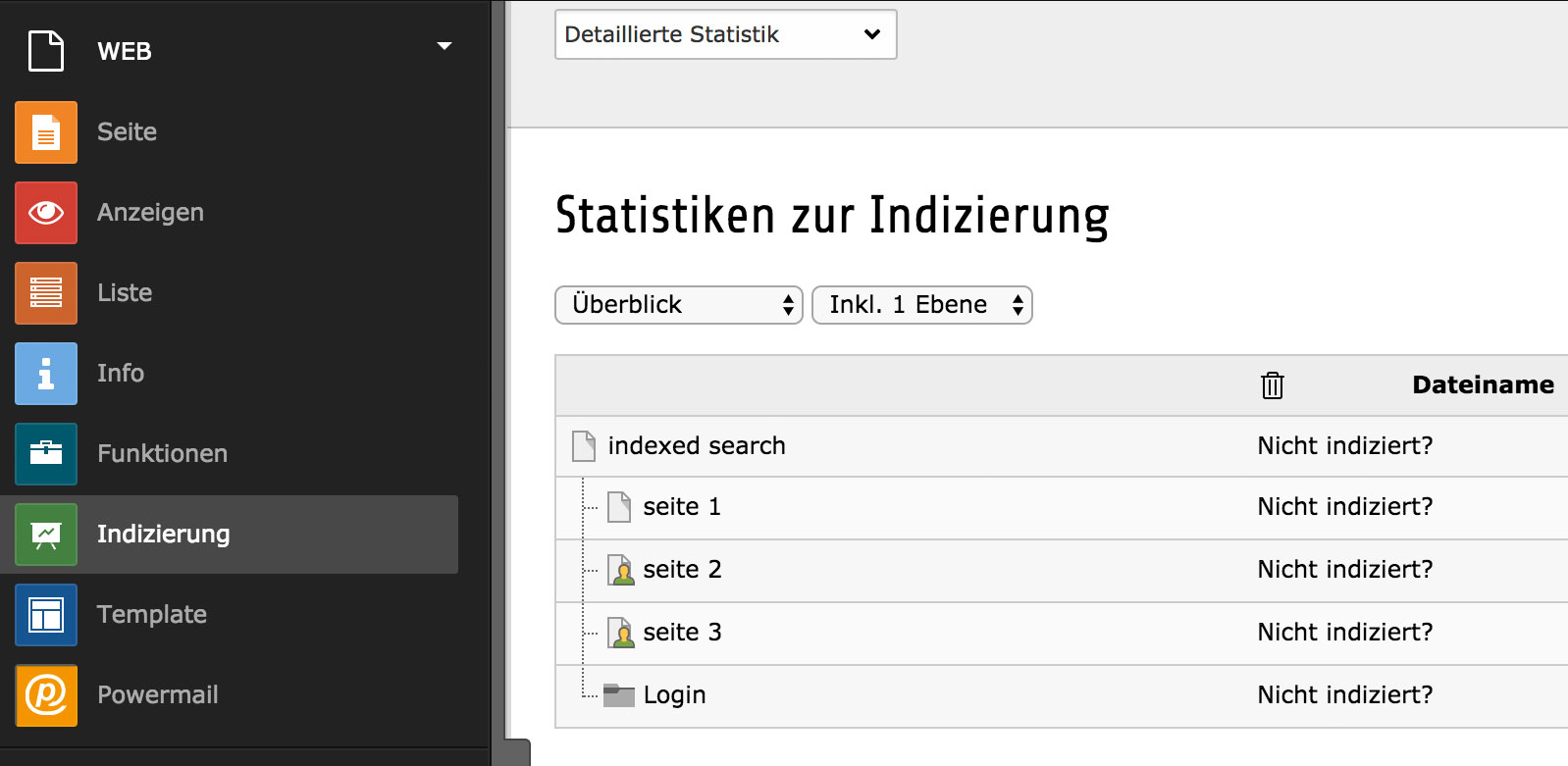
Abbildung 2
Indizieren über das Modul „Info“ / „Site-Crawler“
Machen wir zu Testzwecken einige textliche Änderungen auf unseren Seiten, verlinken ein paar PDFs und löschen wir eine eventuell vorhandene Indizierung (mit Hilfe des entsprechenden Moduls, s.o.). Dann gehen wir auf die übergeordnete Seite und wählen das Modul „Info“ und hier den Eintrag „Site Crawler“.
Wir wählen den Eintrag „Start Crawling“.
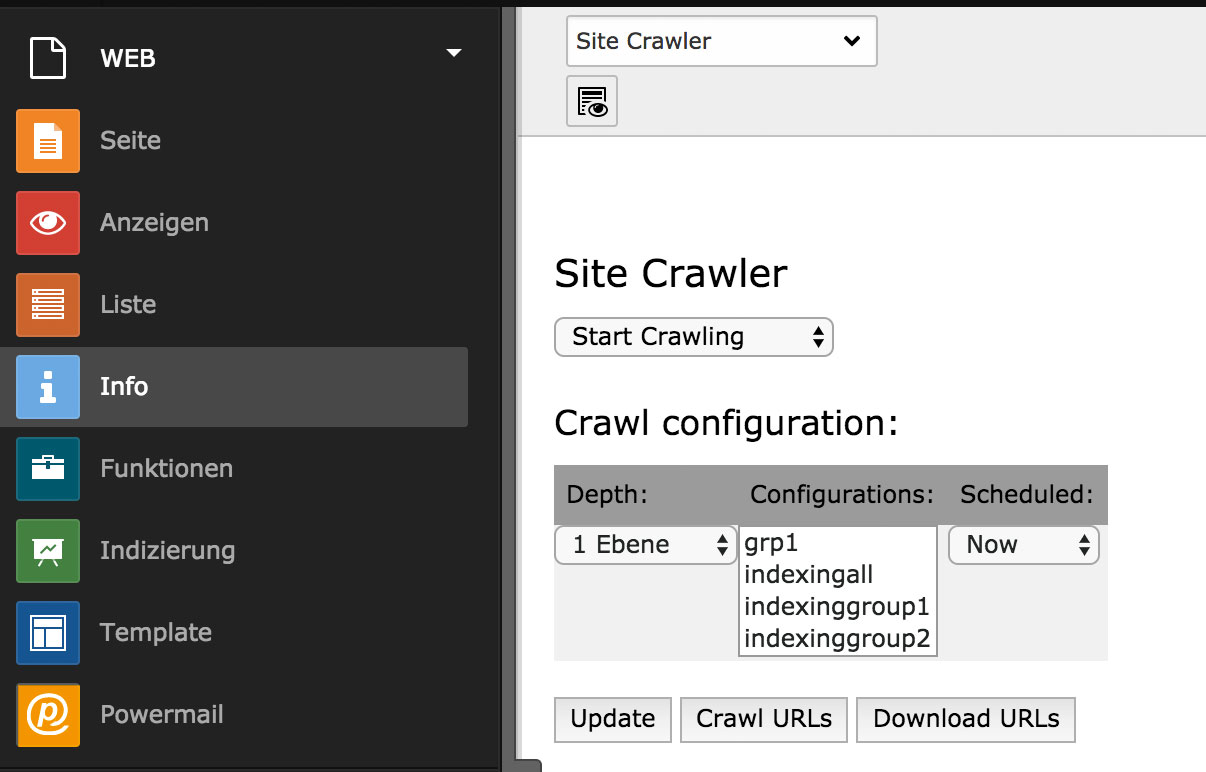
Abbildung 3
Unter „Configurations“ stehen uns die angelegten Crawler Konfigurationen zur Verfügung. Wir markieren die gewünschten Einträge (in diesem Beispiel alle), klicken dann auf „Update“ und als nächstes auf „Crawl URLs“. Danach klicken wir auf „Continue and show log“.
Wir sehen dann eine Übersicht der „Queue“ und stellen fest, dass die eigentlichen Indizierungen noch nicht ausgeführt sind, d.h. die Einträge in der Spalte „Run-time“ sind leer bzw. mit alten Daten gefüllt.
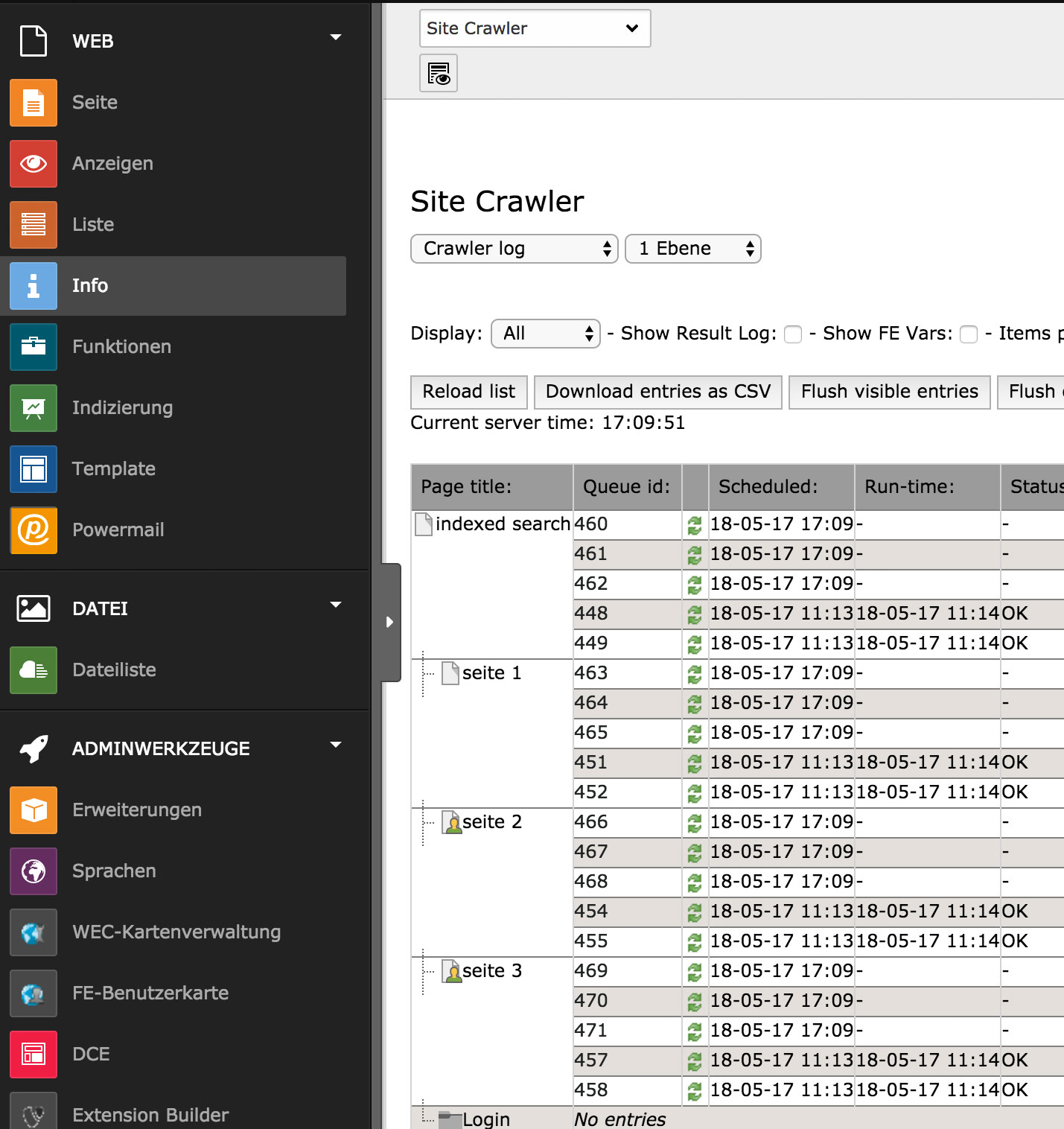
Abbildung 4
Um die Indizierung anzustoßen, muss man in jedem Eintrag auf den Aktualisierungsbutton klicken – „Read“, so lautet der Tooltip des Buttons.

Abbildung 5
Hat man das für alle Einträge gemacht, ist die Indizierung geschehen, was man leicht über das entsprechende Modul nachprüfen kann (oder man testet das direkt in der Suche – am besten gleich für die User der einzelnen Gruppen).
Dieses Verfahren ist natürlich umständlich und bei größeren Webseiten undurchführbar. Hier kommt besser der „Planer“ zum Einsatz.
Indizieren über einen Cronjob / „Planer“
Bevor der Planer verwendet werden kann, muss zunächst ein Backend-Benutzer _cli_crawler angelegt werden (keine Adminrechte, beliebiges Passwort, keine weiteren Einstellungen). Außerdem muss ein ebensolcher mit dem Namen _cli_scheduler vorhanden sein.
Im „Planer“ wählen wir in der Select Box oben den Eintrag „Information“ und stellen fest, dass es 4 verschiedene Jobs für den Crawler gibt.
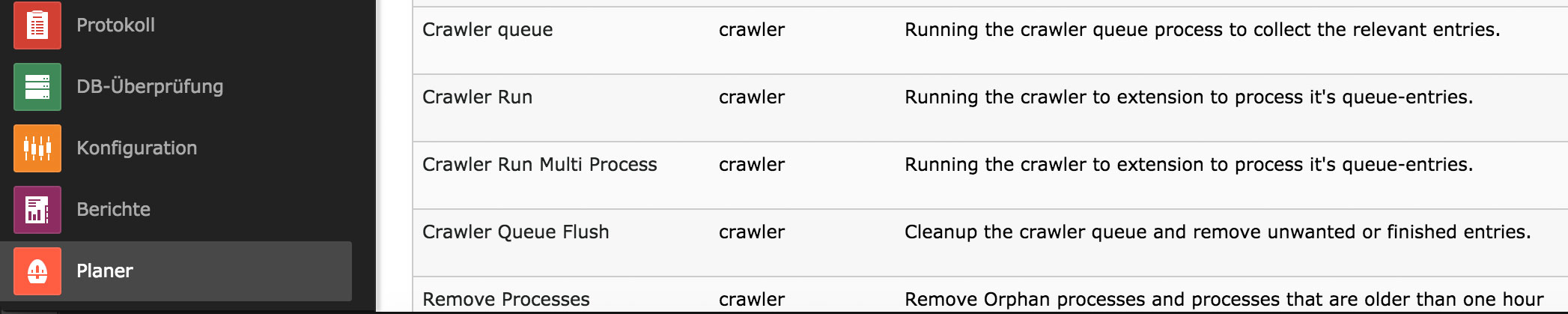
Abbildung 6
Für unser Beispiel benötigt und konfiguriert man zwei: „Crawler queue“ und „Crawler Run“. Zu diesem Zweck öffnet man die Konfigurationseinstellungen und ändert zu Testzwecken zunächst den „Typ“ auf „einmalig“. Im „Crawler Run“ ist nichts weiter zu tun als ihn zu speichern; im „Crawler queue“ kann man per „Start page“ und „Depth“ die zu indizierenden Seiten exakt bestimmen. Wichtig ist in jedem Fall bei „Configuration records“ vor dem Speichern die angelegten Crawler Konfigurationen „indexingall“, „indexinggroup1“ und „indexinggroup2“ (s.o.) allesamt auszuwählen, also zu markieren.
Unter „Geplante Tasks“ sollte das dann in etwa so aussehen:

Abbildung 7
Da beide Jobs zu Testzwecken auf „einmalig“ gestellt wurden (später und im Livebetrieb kann man das natürlich beliebig anders einstellen), können wir sie jetzt starten und danach die Indizierung überprüfen. Zunächst führt man „Crawler queue“ aus, danach „Crawler Run“.
Wenn man Glück hat, hat alles funktioniert und das Modul Indizierung informiert einen darüber. Bei meinen Versuchen kam es auch vor, dass im ersten Lauf die PDFs nicht erfasst wurden und der Job „Crawler Run“ ein zweites Mal gestartet werden musste.
Hinweis: Wenn ein Benutzer mehreren Gruppen zugehörig ist, funktioniert es leider nicht, dass er die Inhalte all seiner Gruppen finden kann – im Gegenteil, er findet gar nichts. Man muss in diesem Fall für die Kombination der Benutzergruppen eine eigene Crawler Konfiguration erstellen. Das klingt umständlich – und ist es auch. Gute Planung, eventuell mit Untergruppen ist in diesem Fall nötig. Danke für den Hinweis an Markus Söth.
Links:
http://xavier.perseguers.ch/tutoriels/typo3/articles/indexed-search-crawler.html
https://docs.typo3.org/typo3cms/extensions/indexed_search/latest/IndexingConfigurations/CrawlerSetup/Index.html
https://docs.typo3.org/typo3cms/extensions/crawler/
https://jweiland.net/typo3/codebeispiele/erweiterungen-anpassen/indexed-search.html